
How we do digital archiving at State Records NSW July 28, 2014

Photo credit: the tools from maine by Denise Carbonell
Right now, State Records’ Digital Archives team is moving from project to normal operations mode. As part of this transition we are publishing our methodology and procedures, providing public access to digital archives from the pilot projects that are open to public access, and inviting NSW agencies to start contacting us to initiate migration projects. We’ll also be sharing as much information as we can about our approach to digital preservation and the tools and technologies that underpin that approach. This post describes some of the key technological choices that we’ve made.
Probably the most distinctive feature of State Records NSW’s approach to preserving digital recordkeeping systems is its flexibility. Rather than delivering a tightly integrated, end-to-end system with fixed rules for archiving digital objects, we’ve developed a project-based methodology that we believe can be applied to the migration of any government digital recordkeeping system to the digital archives. To support this open approach to digital archiving, we have favoured the use of small, simple and flexible tools that we can compose together to achieve the goals of different migration projects.
Storage
All of the Digital Archives content (data and metadata) is stored on EMC Isilon scale-out networked attached storage. The advantage of this system is that it abstracts away repository management issues like bit-level integrity, security, scalability, back-up and disaster recovery. Because it presents as a simple networked file system, we get these benefits without being tied to a particular mode of file storage (such as with a digital asset management system or content-addressable storage).
The unopionated nature of file system storage can be both a blessing and a curse. Without a structured approach, file systems can become very messy places. We’ve adapted the Pairtrees for Object Storage protocol from the California Digital Library to organise the Digital Archive’s file system. This protocol provides a scheme for creating unique folder hierarchies for individual digital objects based on UUIDs.
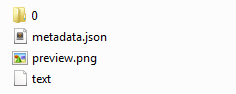 Within those unique folders, we store original digital objects, any additional versions of those objects (created for preservation or access purposes), extracted text, metadata and a preview image according to a very simple scheme displayed in this image.
Within those unique folders, we store original digital objects, any additional versions of those objects (created for preservation or access purposes), extracted text, metadata and a preview image according to a very simple scheme displayed in this image.
Metadata
One of the main files that we store alongside digital objects is the metadata file, entitled “metadata.json”. This file contains:
- original metadata that came with digital objects
- additional metadata that has been automatically or manually created in order to further describe digital objects
- links to State Records NSW’s model of NSW government over time (the entities in our main catalogue Search). These links contextualise recordkeeping systems in the Digital Archives and enable discovery.
- links to access and disposal rules issued by State Records NSW
- preservation, process and chain of custody metadata.
Reflecting the openness of our overall approach, the schema for these metadata files is itself open: it can be updated over time in order to cope with the diverse original metadata that comes with different projects. We call this evolving schema the metadata registry. The metadata registry comprises a custom frontend and a very simple backend, which is just a JSON Schema stored in a public Git repository. Updating the registry just involves pushing changes to that repository.
One of the challenges of having an evolving metadata schema is storing it in a database so that it can be used for queries and reports. Most SQL databases expect a fixed schema that will be rarely changed. This is why we are using a document-oriented NOSQL database, MongoDB, as the secondary store for metadata (the primary storage is the metadata.json files on disk). MongoDB is designed for storing JSON-like documents with a dynamic schema and is a great fit for our needs. We are complementing this with a Solr search index for full text and faceted searching over the contents of the Digital Archive.
Preservation actions
Our approach to preservation actions is akin to our approach to metadata: controlled but flexible. We have a preservation pathways registry that, like the metadata registry, can be updated over time to reflect the different preservation decisions made in different projects. During migration projects we assess the preservation risks and access requirements for the file formats included in that project. If we make a decision to transform a file format, we record that decision in the preservation pathways registry. We use the National Archives UK’s PRONOM registry and DROID tool to uniquely identify file formats. Depending on the demands of different projects, we use additional tools like Apache Tika and Exiftool to further characterise digital objects.
Migration projects
Wherever possible, we’ve adopted existing technologies rather than building our own. To manage the workflow, task scheduling, and collaborative aspects of digital archives migration projects we use Basecamp. As each project concludes, our knowledge and pool of re-usable decisions and practices grows. In addition to the metadata registry and preservation pathways register, we keep details of how we solve particular preservation challenges, useful tools we find, and other resources in a Confluence wiki. We manage in-house code using JIRA, also from Atlassian, and we share as much as we can on Github.

Leave a Reply
You must be logged in to post a comment.